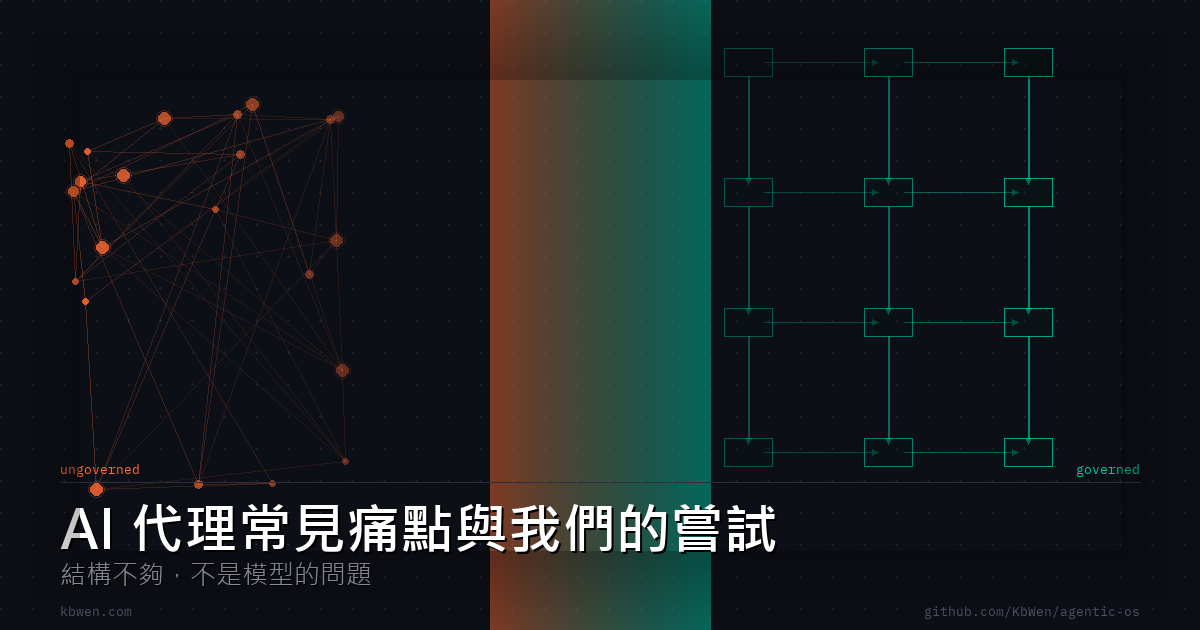
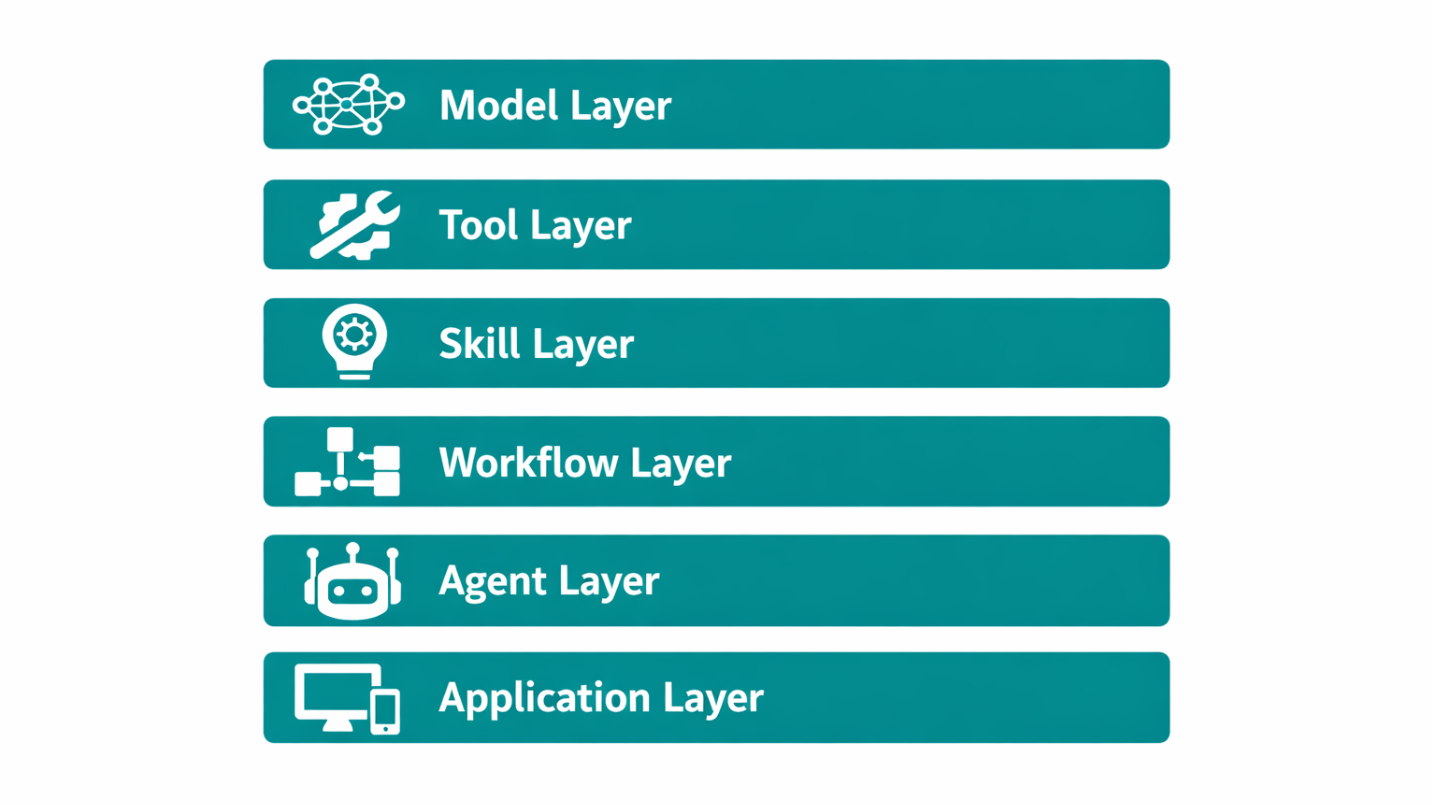
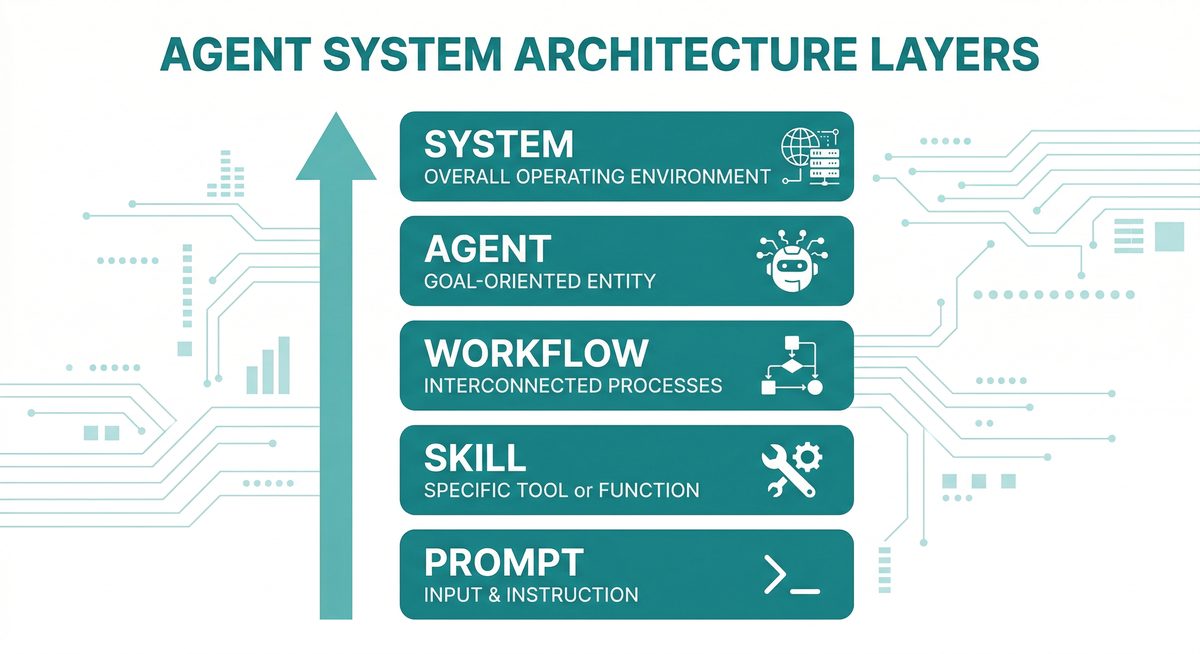
Why AI Agents Go Wrong: It's Not the Model
TL;DR: “The agent did something wrong” usually gets diagnosed as a model problem. Most of the time it isn’t. Capability failures (wrong reasoning) and governance failures (no structure to catch wrong reasoning) look identical from the outside but need completely different fixes. This post is about telling them apart, and why most teams are currently solving the wrong one. The agent said the feature was done. I asked for the commit SHA. There wasn’t one. When I checked the branch, two of the three modules it described implementing hadn’t changed. ...