
Agentic OS
Editor's picks
Agent
See all 19


Agentic OS
See all 19Claude Code
See all 11

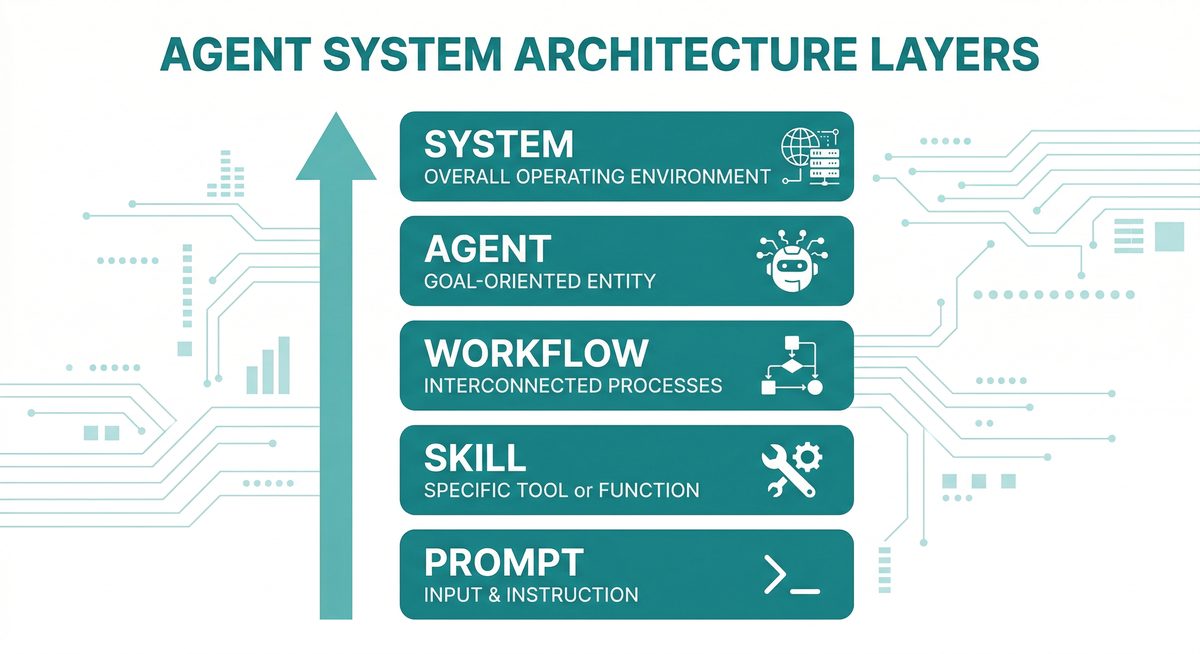
Architecture
See all 10Governance
See all 10


Skills


LLM
Dev Tools
All posts (19)
- Cursor 被 SpaceX 買走了。六百億,15 倍營收,然後呢?
- Cursor Sold for $60B. What That Price Actually Signals.
- When an AI says "done," ask it to show you
- AI 說「完成了」,怎麼確認它真的做完?
- 怎麼讓 AI agent 照流程走:閘門只記帳,不攔人
- Claude Code 多了個 dynamic workflows,我打開那段 JS 看了一下
- How Claude Code's Dynamic Workflows Run 1,000 Subagents
- 怎麼寫你的第一個 skill — 從一個煩躁的 prompt 開始
- 13 行的 skill:AI 起稿,我事後才看懂
- Skill 邊界設計:從能力到合約
- Skill Design as Interface Design
- Token 成本的真相:分級,但別分太細
- Token Economics of AI Agent Governance
- No evidence, no completion
- Work Log:跨 session 的記憶機制
- Prior art: what distributed systems already knows
- Why AI Agents Fail in Production
- AI 代理常見痛點與我們的嘗試
- 只會 Prompt 已經不夠了:從「下指令」到「蓋系統」的思維進化