
Governance
Editor's picks
Governance
See all 17




Agent
See all 15
Agentic OS
See all 10


Claude Code
See all 9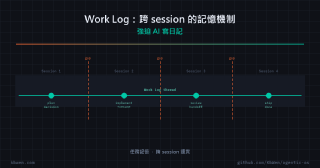
Architecture

LLM
Token Economics
Benchmarks
All posts (17)
- When an AI says "done," ask it to show you
- AI 說「完成了」,怎麼確認它真的做完?
- Claude Fable 5: First Public Mythos-Class Model, One Day In
- Claude Fable 5 是什麼?第一個公開的 Mythos 級模型,加上我第一天的使用心得
- 怎麼讓 AI agent 照流程走:閘門只記帳,不攔人
- Benchmark 飽和,其實是個驗證問題
- LLM Benchmark Saturation Is a Verification Problem
- MCP 資安危機:問題出在治理
- MCP Security Is a Governance Problem
- Token 成本的真相:分級,但別分太細
- Token Economics of AI Agent Governance
- No evidence, no completion
- Work Log:跨 session 的記憶機制
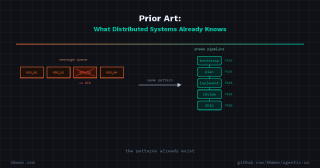
- Prior art: what distributed systems already knows
- 只用 Prompt 和技能,也能做到基本治理
- Why AI Agents Fail in Production
- AI 代理常見痛點與我們的嘗試