利用 CNN 來預測數字 (MNIST)
輸入圖形是一個 2828 灰階 0~9 的數字。輸出是一個 110 的矩陣,代表預測 0~9 的機率分布。
流程如下:
輸入 – convolution – pooling – convolution – pooling – hidden layer – output
在代碼中用到 [None, xx, xx] 和 [-1, XX, xx],代表我們忽略輸入的大小(batch size),它會跟隨著輸入自動改變。
max pooling 表示我們選擇的是那個 kernel size 裡的最大值。結構中也加入了 dropout 來避免 overfitting。
結果
上圖是沒有 dropout,下圖是有 dropout。就這個例子而言差別不大,但還是看得出來上面的訓練會比測試好。
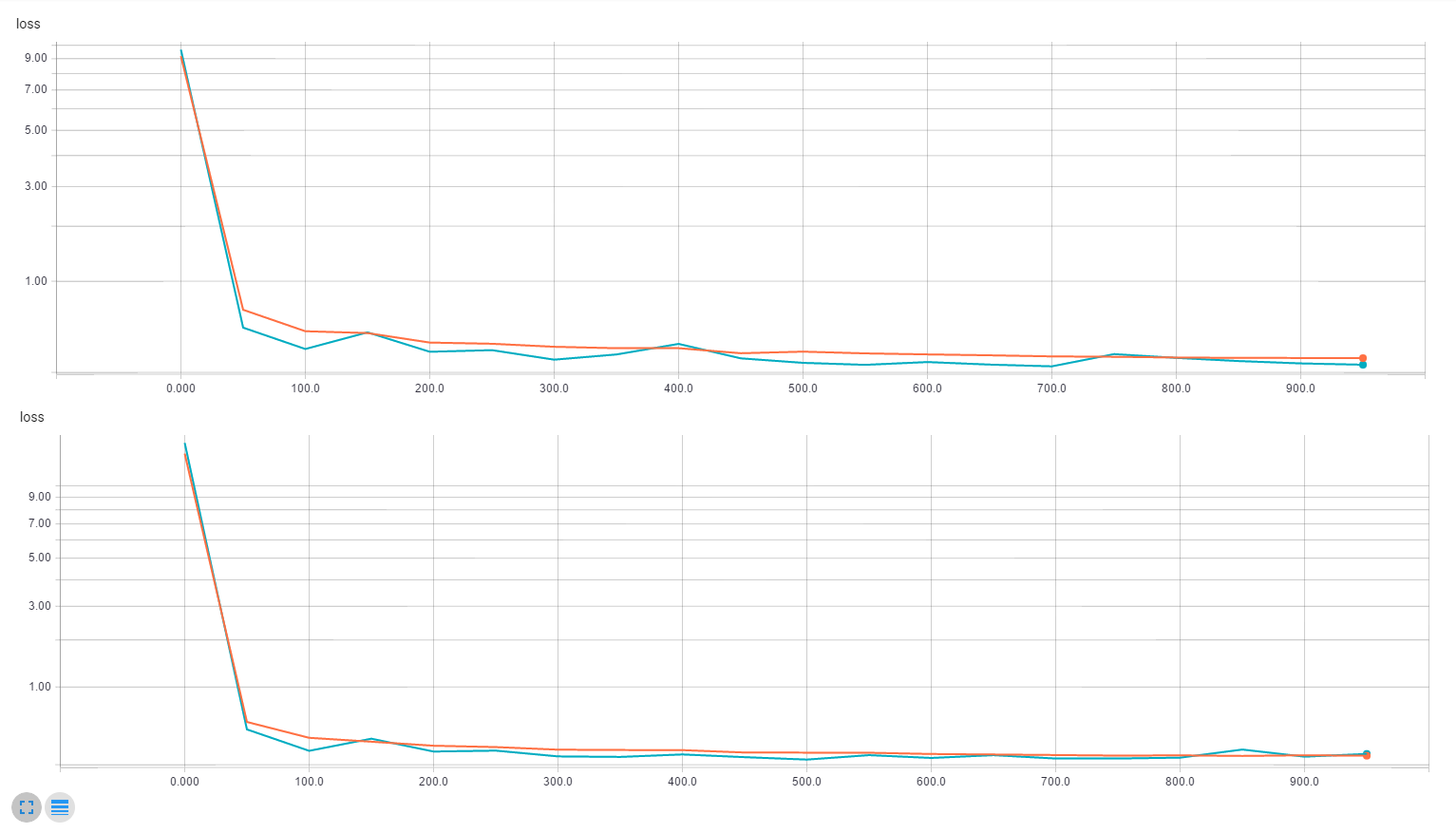
準確率落在 97%~99% 之間 (1000 次訓練)。
(目前使用 GradientDescent,更換優化器應該會更好)。