把字詞轉成 word embedding
要在字詞中找到他們之間的某種關聯,而不只是分散無意義的符號代表。
做這個問題的核心概念是: 「假設兩個不同句子中的詞上下文相同,則代表兩個詞的語意相近。」
今天要來使用 skip-gram 模型,一個類似二元分類的方式 (判斷像或是不像)。一開始也同之前的問題,先做數據處理。
- 計算出現數量:
[(most count word1, n1), (second word2, n2)] - 文字轉成向量:
例如:The actual code for this tutorial is very short
生成的 skip-gram pairs 示意:
([the, code], actual),([actual, for], code), …(actual, the),(actual, code),(code, actual), …
在這之間都會給他編號,轉化為 (10, 20), (10, 30), (30, 10), (30, 40) ... 的形式。
用到 nce_loss,目前我還不是非常熟練,概念上是讓目標詞的機率越高越好,並讓其餘 K 個負面樣本 (negative samples) 的機率降低。
經典案例:
king - queen = man - woman ==> king - queen + woman = man
給 queen 加上負號,並取不要的值,我想是這種感覺吧?
結果
會把相似的詞分的近一些:
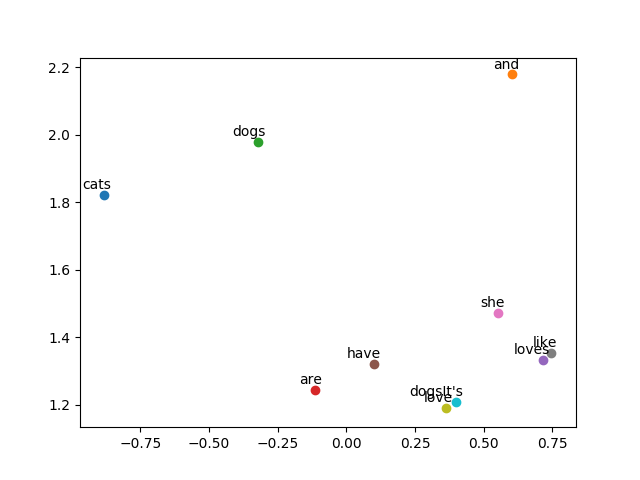
原版 tensorflow 範例有用上 sklearn 的 TSNE 來做降維,在很多地方都比 PCA 效果好。