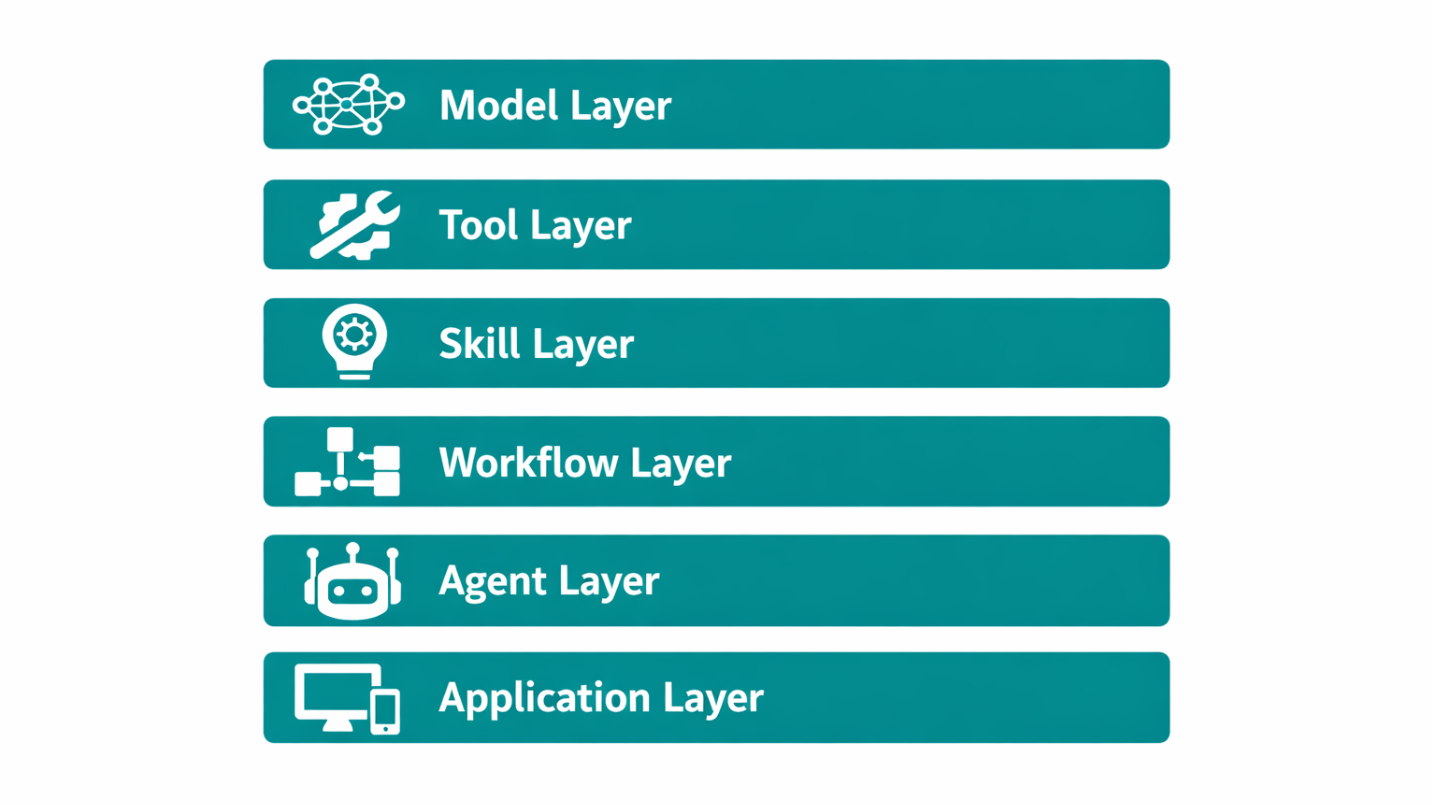
Prompt Engineering
Editor's picks
Prompt Engineering
See all 14

LLM
See all 11

Agent
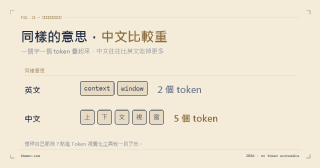
Token Economics
Claude Code
ChatGPT
Claude
Gemini
All posts (14)
- 只會 Prompt 已經不夠了:從「下指令」到「蓋系統」的思維進化
- What Makes an AI Skill Different from a Prompt?
- Agentjacking: how a fake bug report hijacks your coding agent
- Agentjacking:一封假錯誤報告,就能讓 coding agent 替駭客跑指令
- How Many Tokens Is Your Prompt Actually Using?
- 你的 Prompt 到底花掉多少 Token?
- Does Saying 'Thank You' to ChatGPT Actually Cost Anything?
- 跟 AI 說「請」和「謝謝」,到底有沒有差?
- Why Does AI Sound So Confident When It's Wrong?
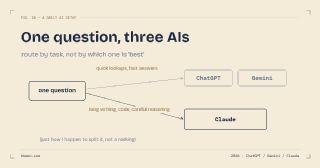
- How I Use ChatGPT, Claude, and Gemini Day to Day
- 為什麼 AI 唬爛的時候,口氣跟講真話一模一樣?
- 我每天開著三個 AI 聊天視窗,這陣子摸出來的幾個小習慣
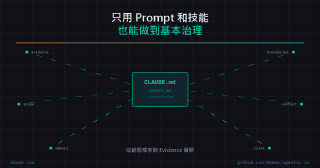
- 只用 Prompt 和技能,也能做到基本治理
- 《大語言模型 LLM:其實做的事情比你想像中更單純》